
This was really cool – they compared Large Language Models (LLMs), like ChatGPT to human experts in product risk assessment.
Any paper that found something to be “deceptively eloquent” (great term) is worth reading in my view.
They compared the assessments of six consumer products, which included FMEA, risk mitigation identification and more; lots of data and outputs you can review.
It’s open access, so you can check it out yourself.
Some notable findings:
· They “found that ChatGPT generally performed better at divergent thinking tasks such as brainstorming potential failure modes and risk mitigations”
· However “there were errors and inconsistencies in some of the results, and the guidance provided was perceived as overly generic, occasionally outlandish, and not reflective of the depth of knowledge held by a subject matter expert”
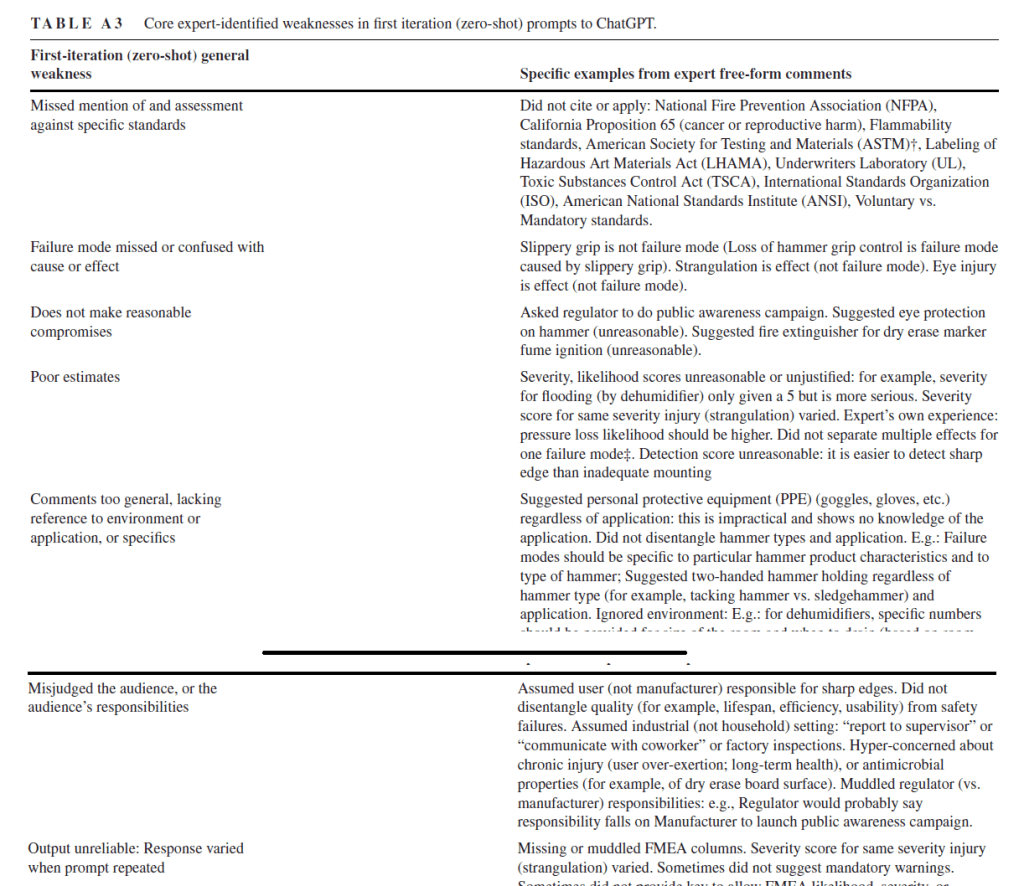
· Further, LLMs produced “omissions, outlandish suggestions, unjustified estimations and deductions, over-generality, and audience or context confusion”
· When tested against a sample of other LLMs, similar patterns in strengths and weaknesses were observed
· They say “ChatGPT was deceptively eloquent in its product risk characterizations: outputting responses that product safety experts found to be articulate and somewhat helpful, but deeply flawed in various respects”.
The LLMs also seemed to fall short based on some criteria for evaluating research contributions:
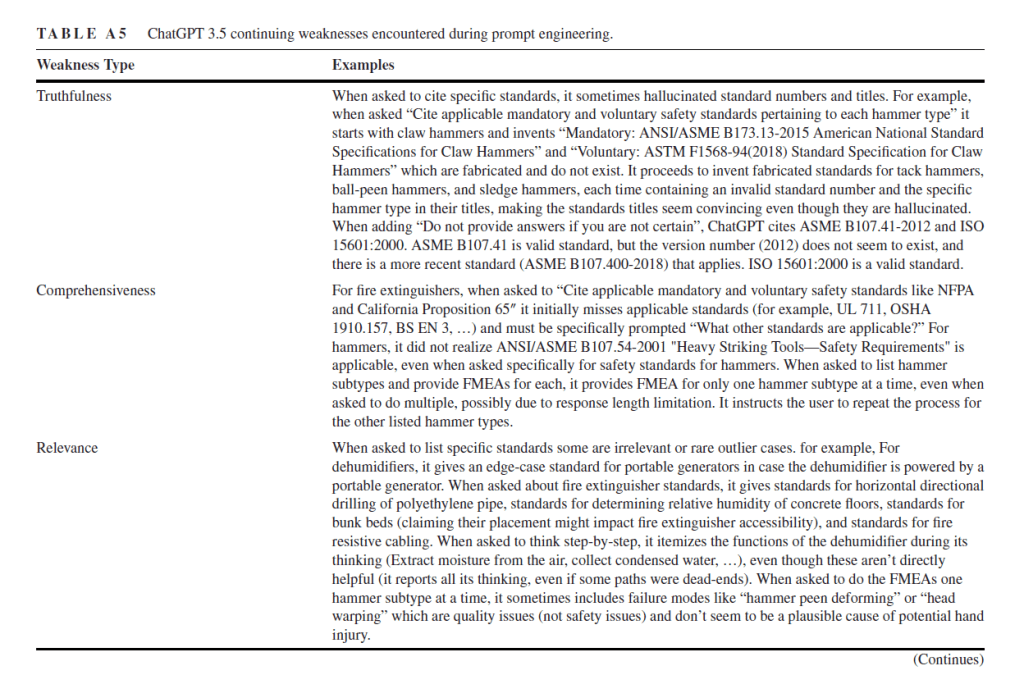
1. is it true? The severity and likelihood scores from LLMs didn’t “seem to be based in fact”
2. Is it new? The safety hazards were largely the highly publicized ones already well-known
3. Is it interesting? LLMs may “partially succeed here, though subject to the veracity and novelty limitations
Other findings:
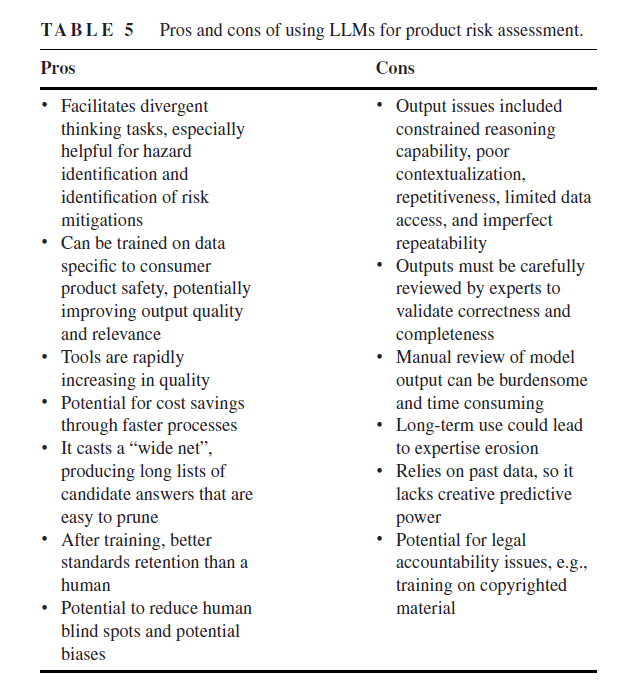
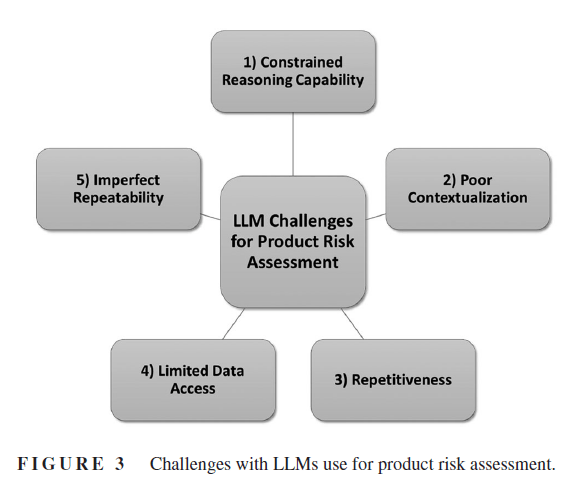
· LLMs missed mention of and assessment against standards
· Failure modes missed or confused with cause or effect
· Didn’t make “reasonable compromises”
· Poor estimates
· Misjudged the audience
· Unreliable outputs, where responses varied when prompt repeated
· And other issues with truthfulness, comprehensiveness and relevance

Ref: Collier, Z. A., Gruss, R. J., & Abrahams, A. S. (2024). How good are large language models at product risk assessment?. Risk Analysis, 1–24.
Study link: https://doi.org/10.1111/risa.14351
My site with more reviews: https://safety177496371.wordpress.com

One thought on “How good are large language models at product risk assessment? [Spoiler: Not very…yet]”