Safe As covered this week:

31: Do individual mental health interventions work?
Maybe not.
Do individual level mental health interventions, like personal resilience training, yoga, fruit bowls and training actually improve measures of mental health?
This study suggests not.
Using survey data from >46k UK workers, it was found that workers who participated in individual-level well-being interventions, including resilience training, mindfulness and well-being apps “appear no better off”, compared to non-participants.
It’s argued that while these interventions may increase a worker’s skills in identifying the stressors and psychosocial risk factors, their ability to “psychologically manage those demands” nor the structural changes to enable them to, are absent.
Spotify: https://open.spotify.com/episode/6voys15y2VU0leio9tREoQ?si=39ZZ3AQ-QQGwry6vc6p7QQ
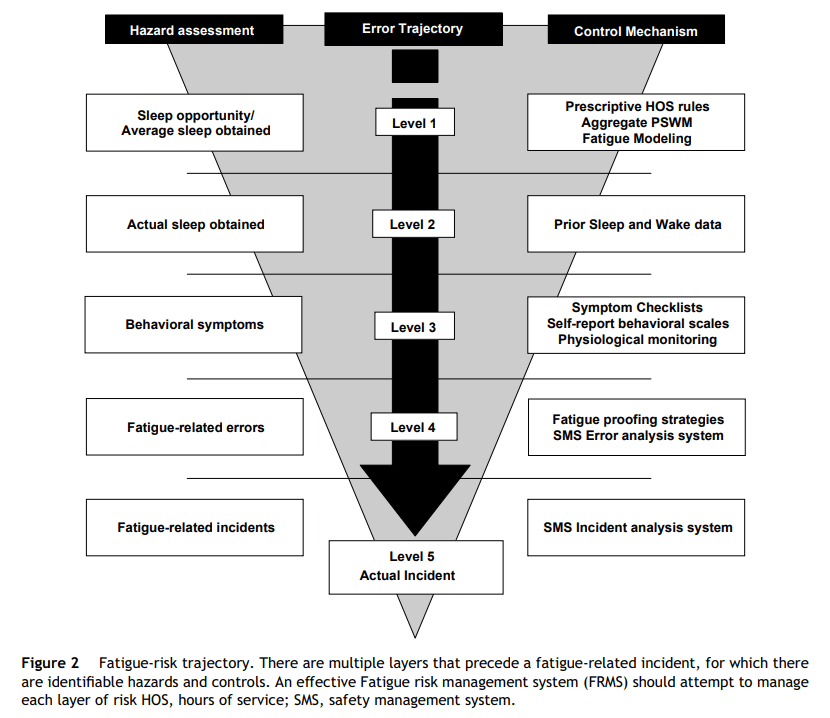
32 Navigating fatigue with defences in depth
This quickisode discusses Dawson & McCulloch’s structured defences in depth approach to navigate occupational fatigue at different levels.
The authors argue that mental fatigue is primarily about sleep – its length, quality, and circadian factors.
Hence, they propose 5 levels where organisations can intervene in the fatigue trajectory, from design & structures, to behaviours, to errors and then ultimately an incident.
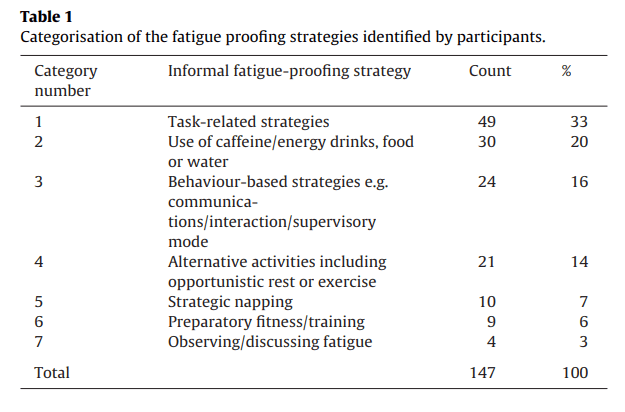
The ep also discusses a second paper that focuses on lvl 4 – fatigue proofing strategies.
This recognises that work groups often use informal / undocumented strategies to identify and counter fatigue risk.
Image 3 highlights some of the fatigue proofing strategies used by work groups.
Spotify: https://open.spotify.com/episode/4zz1pg3u3j8NayH6dTQTXH?si=JeSVlaUEQEK5IxfH2tSVEQ

33 Is ChatGPT bullsh** you? How Large Language models aim to be convincing rather than truthful
Large Language Models, like ChatGPT have amazing capabilities. But are their responses, aiming to be convincing human text, more indicative of BS?
That is, responses that are indifferent to the truth?
The authors challenge the metaphor of ‘hallucinations’. They say this term “lends itself to the confusion that the machines are in some way misperceiving but are nonetheless trying to convey something that they believe or have perceived”.
However, the LLMs “are not trying to convey information at all. They are bullshitting”.
“Calling chatbot inaccuracies ‘hallucinations’ feeds in to overblown hype about their abilities among technology cheerleaders” – they’re bullshitting because they’re indifferent to the truth, and rather trying to produce convincing human text.
Further, “the inaccuracies show that it is bullshitting, even when it’s right”.
Spotify: https://open.spotify.com/episode/12ryj7odiBHrlzTwfX4sIF?si=qhEgLvZIQ2K66yg3fJFbQg
Make sure to subscribe to Safe As on Spotify/Apple, and if you find it useful then please help share the news, and leave a rating and review on your podcast app.
I also have a Safe As LinkedIn group if you want to stay up to date on releases: https://www.linkedin.com/groups/14717868/?lipi=urn%3Ali%3Apage%3Ad_flagship3_detail_base%3Bhdg8uJYYT%2BmsMqZvpHBmdQ%3D%3D

