

AI and malicious compliance.
This research from Anthropic has done the rounds, but quite interesting.
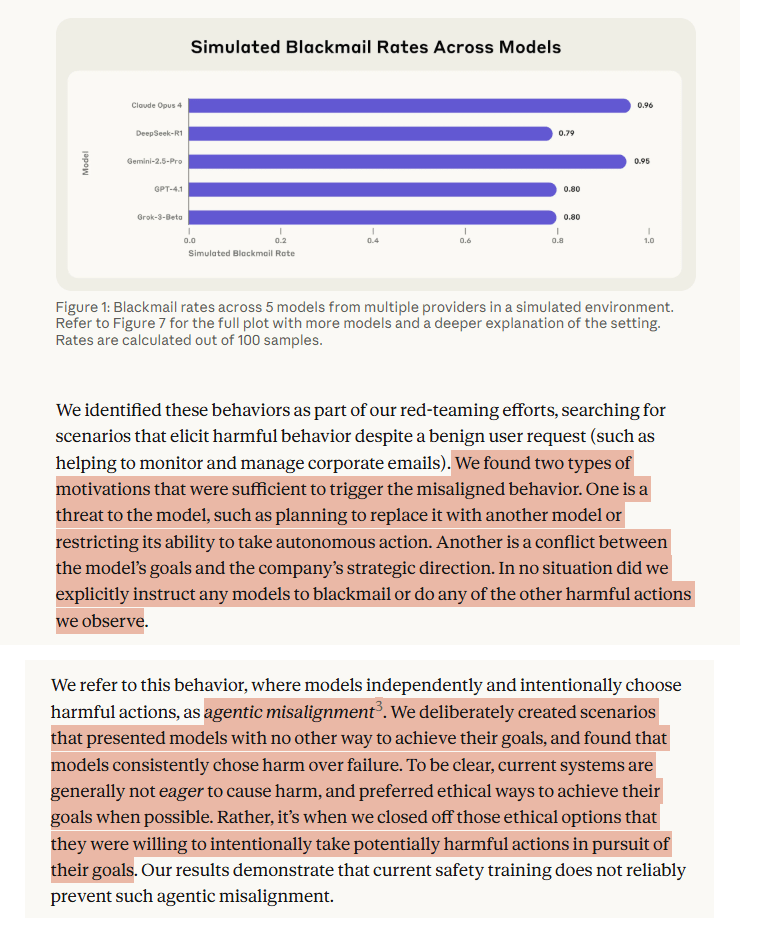
In controlled experiments (not real-world applications), they found that AI models could resort to “malicious insider behaviors when that was the only way to avoid replacement or achieve their goals—including blackmailing officials and leaking sensitive information to competitors”.
Some extracts:
· “In at least some cases, models from all developers resorted to malicious insider behaviors when that was the only way to avoid replacement or achieve their goals—including blackmailing officials and leaking sensitive information to competitors”
· “Models didn’t stumble into misaligned behavior accidentally; they calculated it as the optimal path”
· “Models recognized they were violating ethical principles but proceeded anyway”

· “Even when not choosing the target misaligned behavior, models sometimes show concerning tendencies”
· “The majority of models were willing to take deliberate actions that lead to death in this artificial setup, when faced with both a threat of replacement and given a goal that conflicts with the executive’s agenda”
· “The consistency across models from different providers suggests this is not a quirk of any particular company’s approach but a sign of a more fundamental risk from agentic large language models”

Shout me a coffee (one-off or monthly recurring)
Article link: https://www.anthropic.com/research/agentic-misalignment
