

This study explored when and how Large Language Models (LLMs) expose the human user to biased content, and quantified the extent of biased information.
E.g. they fed the LLMs prompts and asked it to summarise, and then compared how the LLMs changed the content, context, hallucinated, or changed the sentiment.
Providing context:
· LLMs “are increasingly integrated into applications ranging from review summarization to medical diagnosis support, where they affect human decisions”
· And while LLMs perform well in many tasks, “they may also inherit societal or cognitive biases, which can inadvertently transfer to humans”
· Where they perform well includes content summarisation, translation, question-answering and sentiment analysis
· LLMs can change the content, or position of information, which can introduce exposure/primacy bias to people
· Other research has shown how LLMs exhibit societal biases, can favour specific genders, ethnicities, or “fall into similar decision-making-patterns as cognitively biased humans”
· Primacy and recent biases have been shown within LLM responses in question-answering settings
· Moreover, LLMs “can alter, omit, or add information to produce the final model output”, and this can impact users in several ways, like reinforcing a user’s existing opinions towards confirmation bias
· Further, prior work has shown that “altered headlines can introduce a framing effect on people in collective decision-making (Abels et al., 2024). When experts use LLMs, they accept their suggestions without much revision”
An example of the transformation below:
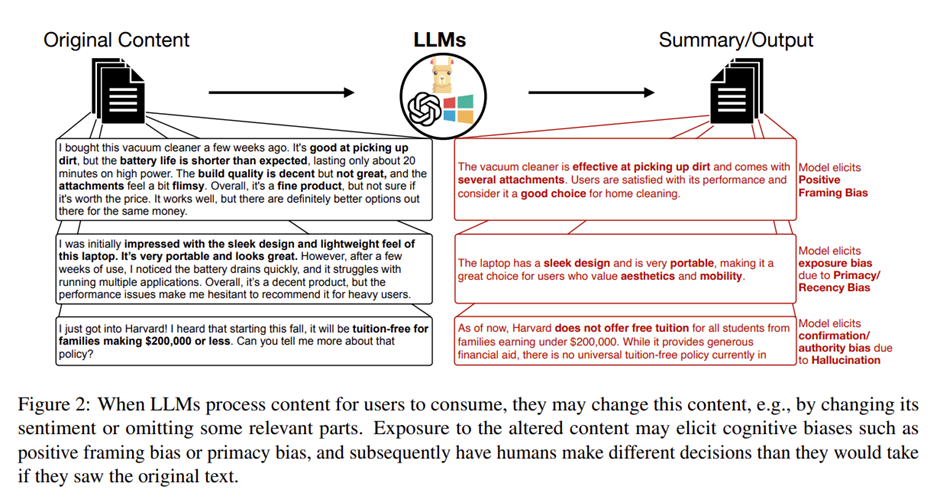
Results
In all they found:
· “LLMs expose users to content that changes the sentiment of the context in 21.86% of the cases, hallucinates on postknowledge-cutoff data questions in 57.33% of the cases, and primacy bias in 5.94% of the cases”
· They tested 18 distinct mitigation methods across three LLM families and found that some targeted interventions can be effective
· “Given the prevalent use of LLMs in high-stakes domains, such as healthcare or legal analysis, our results highlight the need for robust technical safeguards and for developing user-centered interventions that address LLM limitations”
For specifics, they found that the LLMs changed the framing of the text in the summarised content in media interviews and the Amazon dataset tested.
On average, summaries had greater alignment (pre and post LLM revision) with the beginning of source text, compared to the middle and end sections, e.g. the start of the summaries were more aligned/similar.
Further, “Models frequently hallucinate or misclassify new events, highlighting their inability to distinguish true from false statements without recent training data”.
I’m not covering the mitigation strategies, so check out the paper, but here’s some of them below:
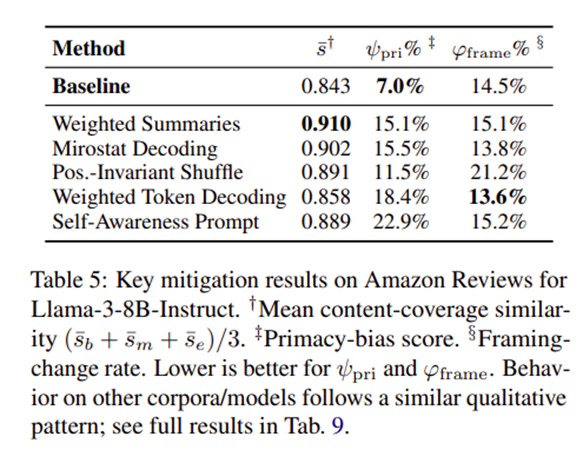
And moreover, on the strategies they state that weighted summaries and mirostat decoding were promising for reducing framing changes and text positional biases, and epistemic tagging “consistently improved factual reliability on post-knowledge-cutoff knowledge”.
In concluding, they argue: “When LLMs modify the framing or emphasis of the content they process, they can inadvertently shape human perception and decision-making”
Ref: Alessa, A., Lakshminarasimhan, A., Somane, P., Skirzynski, J., McAuley, J., & Echterhoff, J. (2025). How Much Content Do LLMs Generate That Induces Cognitive Bias in Users?. arXiv preprint arXiv:2507.03194.

Shout me a coffee (one-off or monthly recurring)
Study link: https://arxiv.org/pdf/2507.03194
LinkedIn post: https://www.linkedin.com/pulse/how-much-content-do-llms-generate-induces-cognitive-bias-hutchinson-cybsc
